사람 뇌의 fMRI는 흐릿한 추정이다. 그러나 LLM은 모든 뉴런·모든 층을 한 치의
오차도 없이 읽고, 일부를 직접 꺼볼 수도 있다. 그래서 신경과학이 "모호하다"며 미뤄둔 질문들을 우리는
결정적으로 답한다. 발견을 하나씩, 왜 → 무엇 → 증거로 차분히 풀어본다.
🎯 왜 중요한가
🔬 무엇인가
📊 증거(실측)
SCROLL ↓
왜 이것이 새로운가
비대칭 — fMRI는 추정하고, LLM은 측정한다
fMRI는 뉴런을 직접 못 본다. 한 칸(voxel)이 약 100만 개 뉴런의 평균이며 느리고 잡음이
많다. LLM 스캐너엔 이 한계가 하나도 없다 — 정확·완전·무손실·인과 개입 가능.
0
fMRI voxel 하나가 뭉뚱그리는 뉴런 수
0
LLM에서 우리가 읽는 단위 — 정확히 하나씩
0
관측 범위 — 모든 층·가중치·인과 개입
들어가기 전에 · 5분 사용설명서
먼저, 이 글에 나오는 용어와 점수 풀이
이 보고서는 뇌과학과 AI의 전문용어를 함께 씁니다. 처음 보는 약어나 숫자가 나오면 언제든 여기로 돌아오세요 —
모두 일상어와 비유로 풀어 두었습니다. 사실 딱 두 가지만 머리에 넣으면 거의 다 읽힙니다:
① AI가 떠올리는 '개념'은 숫자들이 가리키는 방향(화살표)으로 저장되고,
② 우리는 그 화살표를 읽기만 하는 게 아니라 직접 켜고 끌 수도 있다는 것. 나머지는 이걸 재는 자(尺)일 뿐입니다.
💡 점수를 읽는 한 가지 요령:
거의 모든 숫자는 “우연히 찍었을 때 나오는 값”과 비교해서 봅니다. 그 우연값보다 확 높으면 “진짜 정보가 들어 있다”,
우연값과 비슷하면 “아무것도 없다(null)”는 뜻입니다.
밝혀낸 사실들 · 하나씩
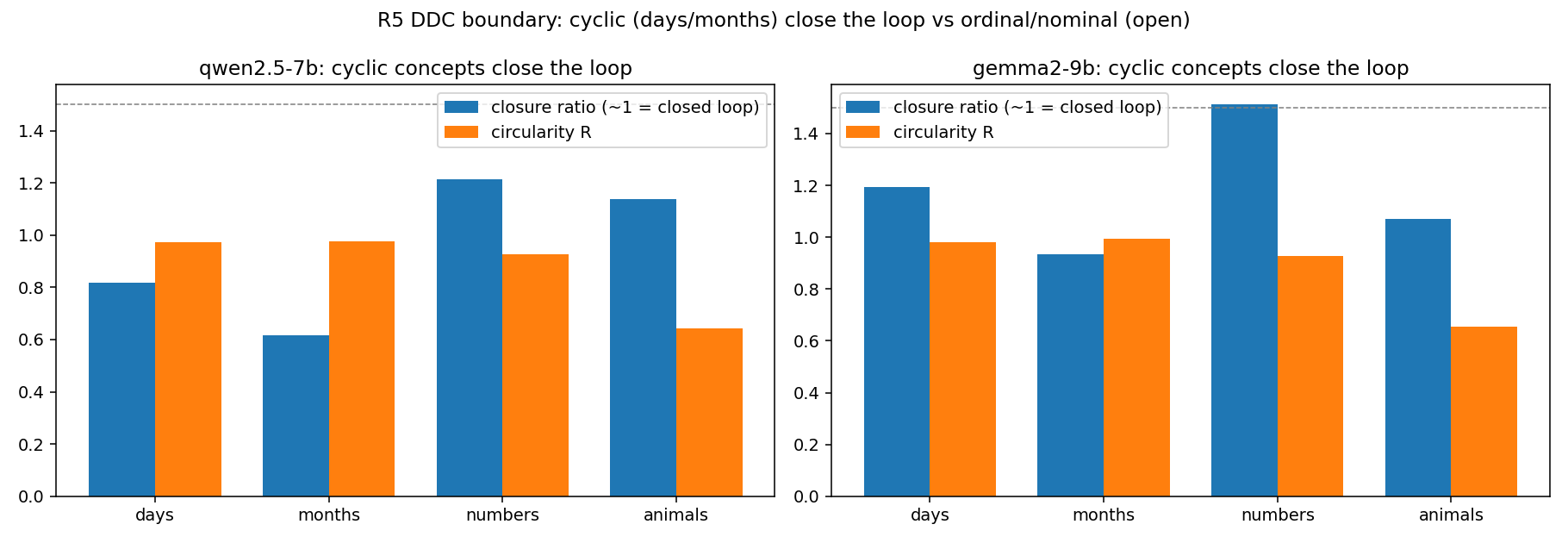
심화 · DDC-Depth (발견 17–21)
개념 하나가 신경망의 얼마를 차지하는가
발견 15·16이 '의미는 방향'임을 보였다면, 자연히 다음 질문이 따른다 — 그 방향 하나는 도대체 얼마만 한가?
몇 차원? 몇 개 층에 걸치나? 단의적인가? 서로 직교하나? 더해도 안 망가지나? 그리고 비선형까지 동원하면 방향을
이길 수 있나? 다섯 가지 심화 질문(발견 17–21)에 정면으로 답했다.
개념 하나 = 망 전 깊이를 관통하는,
약 2,000 뉴런에 분산된, 단 하나의(직교 아닌) 방향이며,
그 방향이 곧 코드다.
아래 다섯 카드가 각 질문의 답이다. 단, 이 결론은 한 번 통째로 뒤집힌 뒤
다시 세운 것이다 — 그 정직한 과정이 신뢰의 근거다.
정직한 과학 · DDC-Depth의 1차 반증
처음 답은 전부 'trivial artifact'였다
DDC-Depth의 1차 측정은 비판적 재검에서 통째로 무너졌다. 화려해 보였던 수치들이 사실은
측정 도구의 그림자였던 것이다. 우리는 그 비판을 그대로 반영해 재측정했고, 결과가 살아남았기에 비로소 보고한다.
결정적 정정: word-grouped split
단어가 train/test에 동시에 새지 않도록 단어 단위로 분할하니, 랜덤 초기화(untrained)
모델의 디코딩이 0.50(완전한 우연)으로 깨끗이 붕괴했다. 즉 학습 모델의 0.99는 전부 학습의 산물이며,
구조나 누수의 부산물이 아니다. 이 한 번의 정정이 발견 17–21 전체의 토대를 단단하게 만들었다.
광범위 검증 캠페인 · DDC-Depth (F17–F21)
"이 결론들이 정말 맞나?" — 4방향에서 동시에 때렸다
🎯 왜 중요한가
발견 17–21은 단어 단위 분할로 한 번 살려낸 결론이다. 그러나 "한 데이터셋·한 모델·한 풀링"에서만 맞는
우연일 수도 있다. 진짜 법칙이라면 조건을 바꿔도 무너지지 않아야 한다. 그래서 우리는 결론을
깨뜨릴 작정으로 네 방향에서 동시에 공격했다.
🔬 무엇을 했나 — 4방향 공격
① 모델 크기: Qwen 0.5B→14B 5단계(작은 모델일수록 잘 깨진다). ② 개념 종류: 명사를 넘어
추상·감정·구문·감각(시각/청각/촉각/미각)까지. ③ 풀링: 평균 vs last-token(읽는 위치를 바꿈).
④ 인과: 단순 상관이 아님을 못박기 위해 forward 중 개념 방향 1개를 제거(ablation)하고
정확도가 무너지는지 본다. 총 11개 디코딩 조건 + 3모델 인과 실험.
결과: 폐기 0건 · 핵심 4발견 전부 강화
11개 조건 전부에서: 비선형−선형 gap ≤ +0.003(방향=코드, F21) · 직교차원 ≤ 1(rank-1, F17) ·
가법 retention 1.00–1.01(F20, 최대 1.012) · off-diagonal excess > 0(비직교, F19). 등급이 바뀐 건 단 하나 —
F19의 '단의성'만 모델 의존(Gemma-2에서 강함)으로 정직하게 하향했다.
0
조건 전부 통과 — 5 크기 × 4 개념종류 × 2 풀링
0
필요성 — 개념 방향 제거가 랜덤 방향보다 타격 (Qwen)
0
특이성 — 해당 개념에만 타격, 다른 개념엔 거의 무영향 (Qwen)
0
폐기된 헤드라인 발견 — 전부 생존
🧪
11/11 조건 통과 — 무엇을 바꿔도 네 결론이 버틴다
각 막대 = 한 디코딩 조건. 채워진 만큼이 '선형 방향'의 디코딩 성능(AUC).
막대 옆 ✓는 그 조건에서 4개 발견(rank-1·가법·비직교·방향=코드)이 모두 통과했다는 뜻.
출처: ddc_validation_campaign.json · validate
인과 확증 · 상관이 아니라 필요
⚡
방향 하나를 forward 중에 뽑아내자, 정확도가 무너졌다
🎯 왜 결정적인가
"방향이 개념과 상관있다"와 "방향이 개념을 만든다"는 전혀 다른 주장이다. 후자를 증명하려면
그 방향을 꺼서 모델이 개념을 못 알아보게 만들어야 한다. 우리는 Qwen-7B에서 forward 도중 개념 방향
성분 단 1개를 제거했다.
📊 증거 — 정확도 하락폭(클수록 그 방향이 중요)
개념 방향을 빼면 0.185 추락(0.93→0.75) — 같은 크기의 랜덤 방향(0.002)보다
74배 큰 타격이고, 다른 개념의 방향(0.0014)을 빼는 것보다 132배
특이적이다. Gemma-2도 특이성 86배로 확증. 딱 한 모델, Gemma-4만 무효였다 —
중간층 방향 하나를 빼도 흔들리지 않는 재부호화(recoding) 모델(발견 18)이라, 이론이 예측한 예외다.
한 개념엔 두 개의 거의 수직인 방향이 있다 — 개념을 알아보는 읽기(read) 방향과
만들어내는 쓰기(write) 방향. 글씨를 알아보는 능력과 써내는 능력이 다르듯이.
실용 레시피: 개념 편집·제어는 쓰기(생성) 방향으로 하라. 쓰기 방향은 50칸 전부
(100%) 편집 성공, 읽기 방향은 42%만(작은 모델은 역효과). 활성 스티어링(AI 제어·안전)의 해법이다.
발견 25 · 행동으로 재검증
✍️
"쓰기가 더 잘 고친다"를 순환 없이·실제 생성으로 다시 증명했다
🎯 왜 다시 했나
위 편집 지도는 "편집 성공"을 쓰기 방향이 정의된 바로 그 값으로 쟀다 — 살짝 순환 논증이다. 그래서
단어를 train/test로 나누고(누수 0), 유창성 비용을 맞춘(ppl≤1.5×) 채, 모델이 그 개념을 실제로 말하는지로 다시 쟀다.
🔬 무엇이 나왔나
쓰기(WRITE)는 자유 생성에서 개념을 표면화하는 유일한 방향(on-target 0.12–0.17 vs 읽기 0.01–0.04,
셔플 대비 6–11배). 그리고 이건 비등방성(anisotropy)이 아니다: 읽기 축을 화이트닝해도 격차가 안 닫히고
cos(읽기,쓰기)≈0.02–0.06(거의 수직) — 개념을 탐지하는 방향과 만들어내는 방향은 다른 축이다.
정직한 한계: 효과는 완만하고 개념 의존적(색·음식엔 강하나 동물·얼굴엔 ≈0), 30–50% 누설 있음.
"방향이 곧 손잡이"라면, 실제 제어 성능은 얼마나 좋은가? 선행연구의 강자 BiPO(Cao 2024, 다단계
최적화 스티어링 벡터)를 동일 유창성·동일 크기로 세워 4개 레시피를 겨뤘다 — 방향의 질만 비교되게.
📊 증거 — 개념 표면화율(OTR, 높을수록 좋음)
싼 게 비싼 걸 이긴다: 1-step 쓰기 그래디언트가 BiPO를
행동·logprob 모두에서 못지지 않는다(Qwen에선 BiPO 사실상 실패). BiPO의 진짜 강점은 힘이 아니라 특이성
(Gemma에서 off-target −1.28로 누설을 억제). 그리고 어떤 방법도 분산 개념(동물·차량·얼굴)을 자유 생성으로
끌어내지 못한다 — 발견 1·12와 일관된 천장이다. 다층 주입은 소폭(0.175→0.219) 덤.
지금까지는 "의미가 무엇이고 어디 있나"였다. 이제 가장 큰 질문 — 능력(지능) 자체는 모델 안 어디에 사는가?
같은 가문을 0.5B→14B로 키우면 분명히 더 똑똑해진다(perplexity 21→5). 그 향상은 개념 방향의 정적 기하에 적혀 있을까,
아니면 다른 곳일까? 능력 사다리 + 같은 구조의 랜덤(untrained) 쌍둥이라는, 뇌로는 불가능한 통제로 이걸 갈랐다.
능력은 정적 사진이 아니라
계산에 산다 — 구체적으로 맥락 속 규칙 학습(ICL)이다.
반복되는 교훈(발견 11→23→27): 크기 따라 단조 증가하는 내부 스칼라는 거의 전부 '너비 추적'이라
랜덤 쌍둥이가 똑같이 재현한다. 학습된 능력 신호로 살아남은 건 행동적 ICL-규칙학습 이득 하나뿐이다.
학계의 정설인가?
"방향 = 의미"는 우리가 발명한 게 아니다
이 아이디어는 1980년대 분산 표현부터 이어진 자연어처리·해석가능성의 핵심 정설입니다.
우리는 그 위에 완전 가중치 관측으로 정밀 측정과 새 각도(read/write·영역vs방향·뇌 대조·메커니즘 실측)를
얹었습니다. 계보를 보면: